Google 検索におけるユーザーデータ
結果の自動生成と自動ランク付け
Google のランキング システムは、数千億のウェブページとその他のデジタル コンテンツの中から、最も関連性と有益性が高い結果を選別して一瞬で最初のページに表示するように設計されています。

Google 検索が検索結果を改善し続ける仕組み
検索システムの仕組み
最も有用な情報を表示するため、検索アルゴリズムはさまざまな要因やシグナル(検索クエリの単語、ページの関連性やユーザビリティ、ソースの専門性、ユーザーの位置情報や設定など)を検討します。
それぞれの要素に適用される重みは、検索クエリの性質によって異なります。たとえば、現在のニュース トピックを検索する場合、辞書の定義よりもコンテンツの鮮度がより大きな役割を果たします。
主な Google 検索のシグナルは次のとおりです。
検索クエリの意味
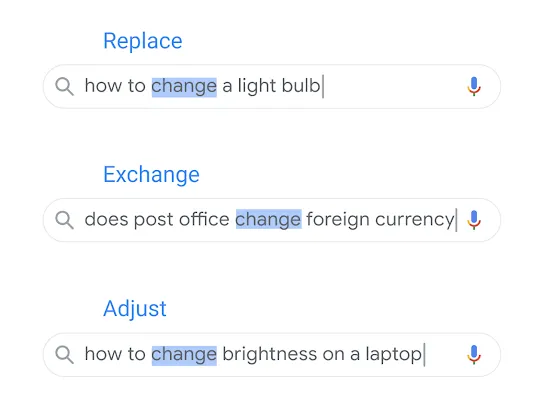
関連性の高い結果を返すには、ユーザーが何を探しているのかを明らかにすること、つまり検索クエリの背後にあるユーザーの意図を理解する必要があります。そのために Google は言語モデルを構築し、ユーザーが検索ボックスに入力した語句が比較的少ない場合でも、利用可能な最も有用なコンテンツを導き出すことができる方法の解明に取り組んでいます。
このシステムは開発に 5 年以上かかりましたが、さまざまな言語での検索の 30% 以上で大幅に検索結果が改善しました。
手順としてはスペルミスを認識して修正するのと同じくらい単純なものですが、さらに高度な類義語システムによって、完全に一致する言葉が含まれていない場合でも、関連性のあるドキュメントを見つけることができます。たとえば、ユーザーは「ノートパソコンの明るさ変更」と検索したものの、メーカーによる記述が「ノートパソコンの明るさ調整」だったとします。Google のシステムは、これらの単語と意図の関連性を理解できるため、ユーザーを適切なコンテンツへ導くことができます。
このシステムは開発に 5 年以上かかりましたが、さまざまな言語での検索の 30% 以上で大幅に検索結果が改善しました。
手順としてはスペルミスを認識して修正するのと同じくらい単純なものですが、さらに高度な類義語システムによって、完全に一致する言葉が含まれていない場合でも、関連性のあるドキュメントを見つけることができます。たとえば、ユーザーは「ノートパソコンの明るさ変更」と検索したものの、メーカーによる記述が「ノートパソコンの明るさ調整」だったとします。Google のシステムは、これらの単語と意図の関連性を理解できるため、ユーザーを適切なコンテンツへ導くことができます。
Google 検索がコンテキストを判断する仕組み
-
キーワード
検索クエリに「料理」や「画像」といった単語を使用すると、Google のシステムはレシピや画像を表示することがユーザーの意図に最も合っていると判断します。
-
言語
検索クエリの言語によって、大半の結果の表示方法が決まります。たとえば、フランス語で検索すると、フランス語の結果が返されます。
-
ローカライズ
Google のシステムでは、ローカル インテントのある多くの検索クエリを認識することもできます。このため「ピザ」と検索した場合は、配達する近くの店舗に関する結果が表示されます。
-
最近の出来事
スポーツの得点や企業収益、あるいはそのときどきの話題を検索すると、最新情報が表示されます。
コンテンツの関連性
次に、Google のシステムではコンテンツを分析して、ユーザーが探している情報に関連のありそうな内容が含まれているかどうかを評価します。
情報の関連性を評価するための最も基本的なシグナルは、検索クエリと同じキーワードがコンテンツに含まれているかどうかです。たとえば、それらのキーワードがウェブページの見出しや本文のテキストに使われている場合、そのページの情報は関連性が高い可能性があります。
定量化可能なシグナルに基づいて関連性を評価しますが、ページのコンテンツの主観的概念(視点や政治的な傾向)を分析するように設計されてはいません。
また、集約、匿名化したインタラクション データを使用して、検索結果が検索クエリと関連性があるかどうかを評価しています。インタラクション データをシグナルに変換すると、機械学習したシステムで関連性をより正しく推定できるようになります。たとえば、「犬」で検索する場合、必要なのは「犬」という単語が何百回も使われているページではありません。アルゴリズムは、「犬」というキーワード以外に、より関連性の高いコンテンツ(犬の画像や動画、犬種のリストなど)がページに含まれているかどうかを評価します。
コンテンツの質
関連するコンテンツを特定した後、最も役に立つと判断されたコンテンツに高い優先順位を付けます。そのために、どのコンテンツが高い専門性、権威性、信頼性を示しているかの判断に役立つシグナルを特定します。
たとえば、品質の判断に使用する要素のひとつに、他の著名なウェブサイトがそのコンテンツをリンクしたり参照したりしているかどうかの把握が挙げられます。これは、一般的に情報の信頼性の高さを示しているためです。Google では、検索品質評価プロセスからのフィードバックを集計し、より正確に情報の質を判定できるようシステムを改善しています。
ウェブをはじめ、あらゆる情報源のコンテンツは常に更新されています。Google では、システムの品質を継続的に測定、評価することで、情報の関連性と権威性のバランスを適正に保ち、検索結果の信頼性を高めていきたいと考えています。
コンテキストと設定
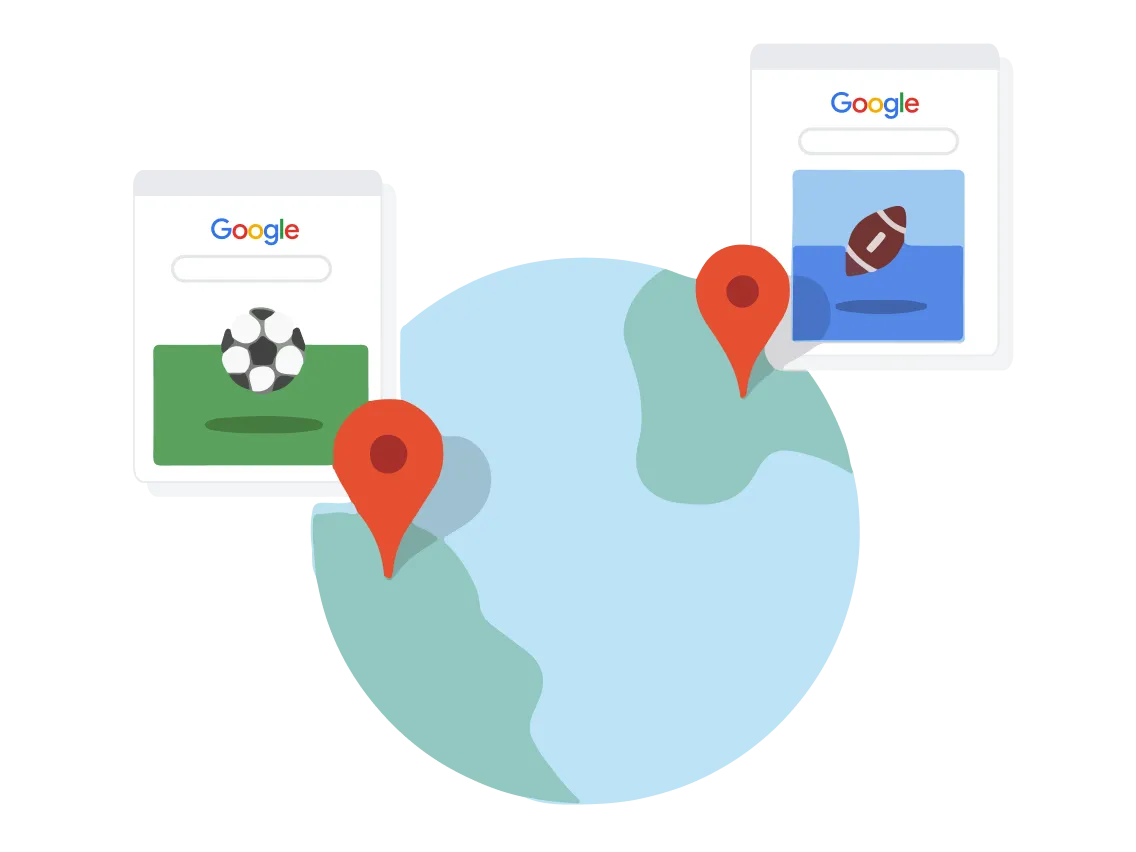
Google 検索では、人間の興味をできるだけ正確な知識へとつなげることを目標としています。その実現のために、Google はユーザーの位置情報、過去の検索履歴、検索設定などの情報を使用して、その瞬間に最も関連性の高い情報を判断しています。たとえば、シカゴで「フットボール」と検索すると、アメリカン フットボールとシカゴ ベアーズに関する検索結果が表示される可能性が高くなりますが、ロンドンで同じ検索をすると、サッカーとプレミアリーグに関する結果が表示されやすくなります。
Google のシステムでは、以前に同じページに複数回アクセスしたことを認識し、そのユーザーの検索結果の上位にそのページを表示させることができます。あるいは、同じ検索クエリが使用された場合、新たな視点やウェブ全体での人気記事を表示する場合もあります。Google 検索上のすべての情報と同様に、Google のシステムでも同じ方法で専門性、エクスペリエンス、権威性、信頼性といった要素に基づいて高品質な情報を表示します。
これらのシステムは、ユーザーの興味や関心に合った情報を提供するために開発されたもので、ユーザーに関するセンシティブな情報(人種、宗教、支持政党など)を推測するようには設計されていません。
具体的なトピックをフォローして情報をタイムリーに取得したり、クリエイターや一般消費者の実体験に基づく知識を探したりするかどうかなど、設定は簡単に変更して自由に管理できます。どれがパーソナライズされた検索結果なのかはいつでも確認でき、設定もいつでも変更できます。
検索アクティビティの設定
Google アカウントにどのデータを保存するかなど、検索エクスペリエンスの向上に使用する検索アクティビティはユーザー自身で変更できます。アカウントのパーソナライズ設定はいつでも更新または変更できます。
設定では、セーフサーチなどのコンテンツ設定もしていただけます。検索結果に一部のユーザーに衝撃を与える可能性のある、刺激の強いコンテンツを含めるかどうかを選択できます。
詳細を見る
-
管理情報
Google 検索で情報が整理される仕組み
-
厳格なテスト
ユーザー エクスペリエンスの継続的な改善
-
スパムの検出
Google 検索でのユーザー保護
-
テクノロジー
検索すると何が起こるのかをご覧いただけます。